🚀 Passing the AWS Certified AI Practitioner (AIF-C01): A Technical, Practical Study Guide

If you’re preparing for the AWS Certified AI Practitioner exam, you’re probably looking for something more useful than a list of services and definitions. This post is a practical guide you can follow end-to-end: what to learn, how to connect concepts, which AWS AI services matter most, and how to think in “exam mode.” I used Stephane Mareek’s Udemy course as my structured backbone, then reinforced it with targeted notes, light hands-on practice, and repetition via exam-style questions.
For the exam, you should build confidence not just in memorization, but in making good AWS service decisions — which is what the exam rewards.
🧭 1) What the exam is really testing
Despite the “AI” label, this exam is less about building models from scratch and more about choosing and operating AI capabilities on AWS responsibly. Expect questions that test whether you can:
✅ Explain core AI/ML concepts (training vs inference, overfitting, evaluation metrics)
✅ Select the right AWS AI service for a business need (vision, text, documents, chat, search)
✅ Understand generative AI basics (foundation models, prompts, retrieval-augmented generation)
✅ Apply responsible AI thinking (privacy, bias, transparency, governance)
✅ Recognize security, compliance, and cost implications at a practitioner level
Exam mindset: you’re being tested as a “smart buyer/operator” of AI, not as a data science researcher.
🧠 2) The minimum ML fundamentals you must be fluent in
You don’t need to derive algorithms, but you do need to speak the language.
🔄 Core lifecycle terms
- Training: Supervised learning, unsupervised learning, self-supervised learning
- Labels: Difference between label and unlabelled data and how it associates with different types of training
- Validation: Tuning a model’s settings on a held-out dataset to prevent overfitting
- Testing: final evaluation on unseen data
- Inference: using the model to produce outputs in production
⚠️ Common failure modes (high value for exam questions)
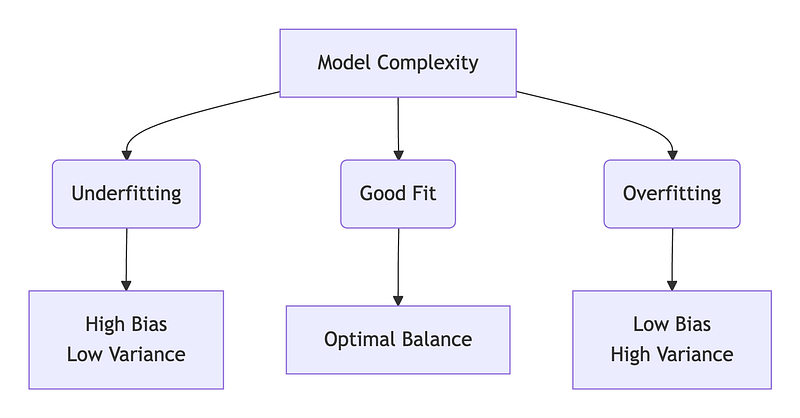
- Overfitting: The model performs exceptionally well on its training data but fails to generalize to new, unseen data. It has essentially memorized the training set rather than learning the underlying pattern.
- Underfitting: The opposite problem. The model is too simplistic and fails to capture the essential trends in the training data, resulting in poor performance everywhere.
- Data Leakage: A subtle but catastrophic error where information from the validation or testing datasets inadvertently influences the training process. This creates an unrealistic performance estimate and guarantees failure in production, as the model has “seen” data it shouldn’t have.
📏 Metrics (know which to use when)
🎯 Precision: Answers “When the model predicts positive, how often is it correct?” Use when false positives are costly (e.g., spam detection, low-priority marketing campaigns).
🔍 Recall: Answers “How many of the actual positives did the model successfully catch?” Use when false negatives are costly (e.g., medical diagnosis, fraud detection in safety-critical systems).
⚖️ F1 Score: The harmonic mean of Precision and Recall. It provides a single balanced score when you need to consider both types of errors.
📊 Confusion Matrix: The foundational table that visualizes all model predictions, breaking them into True Positives, False Positives, True Negatives, and False Negatives. It is the source from which all other classification metrics are derived.
🧠 Types of Machine Learning Models by Learning Approach
Understanding what a model does is important, but understanding how it learns is fundamental. The learning approach you choose dictates the kind of data you need, the problem you can solve, and the very nature of your model’s intelligence.
📘 Supervised Learning: Guided by Examples
Models are trained on labeled data where every input has a known correct output. The goal is to learn the mapping to make predictions on new, unseen data. It’s like learning from an answer key and is used for classification (categories) and regression (numbers).
🧩 Unsupervised Learning: Discovering Hidden Patterns
Models analyze unlabeled data to find inherent structures or relationships without any predefined answers. This approach is used for clustering similar items, dimensionality reduction, and discovering rules.
⚖️ Semi-Supervised Learning: A Practical Hybrid
This method efficiently uses a small amount of labeled data together with a large amount of unlabeled data. It’s a cost-effective solution for real-world problems where full labeling is expensive or impractical.
🎮 Reinforcement Learning: Learning by Trial and Error
An agent learns to make decisions by interacting with an environment, receiving rewards or penalties for its actions. The goal is to master an optimal long-term strategy, making it ideal for robotics, game AI, and autonomous systems.
Don’t be surprised if you are tested throughly on these concepts!
🧰 3) AWS AI Services: Learn Them by the “Job to Be Done”
It’s important to know which AWS service to pick in the exam — Here is a breakdown of core AWS AI services by their primary “job to be done.”
👁️ Computer Vision
Amazon Rekognition: Your go-to for analyzing images and videos. This service can identify objects, people, text, scenes, and activities. It also provides facial analysis and powerful content moderation features.
Typical Use Cases: Content moderation for user-generated media, identifying objects in warehouse footage, verifying identity via facial detection.
📄 Intelligent Document Processing
Amazon Textract: This service doesn’t just perform basic Optical Character Recognition (OCR). It intelligently extracts text, handwriting, and structured data (like forms, tables, and key-value pairs) from virtually any document.
Typical Use Cases: Automating data entry from invoices and claims, extracting information from tax forms and onboarding paperwork for databases.
🎙️ Speech and Language Processing
Amazon Transcribe: Highly accurate speech-to-text service that can add punctuation, format timestamps, and identify speakers in conversations.
Amazon Polly: Turns text into lifelike speech, offering dozens of voices and languages.
Amazon Translate: Provides fast, high-quality, and customizable language translation.
Typical Use Cases: Generating subtitles for media, creating voiceovers, providing real-time translation for customer support chat.
📝 Natural Language Understanding (Classic NLP)
Amazon Comprehend: This service uses machine learning to uncover insights and relationships in text without any ML expertise required. It can analyze sentiment, extract key entities and phrases, automatically classify documents, and detect syntax.
Typical Use Cases: Automatically triaging support tickets by sentiment, analyzing customer feedback, tagging and organizing large document libraries.
🔍 Enterprise Search and Retrieval
Amazon Kendra: A highly accurate, intelligent enterprise search service powered by machine learning. It connects to your internal data repositories (SharePoint, S3, databases, wikis) to deliver precise answers to natural language questions.
Typical Use Cases: An intelligent Q&A system for company policies, a unified search portal for internal research and development documents.
💬 Conversational AI Interfaces
Amazon Lex: The service behind Alexa, it allows you to build conversational interfaces (chatbots and voice bots) using advanced deep learning functionalities for natural language understanding.
Typical Use Cases: A self-service FAQ chatbot for a website, automated voice response systems for contact centers.
📈 Personalization and Forecasting
Amazon Personalize: Enables developers to build applications with real-time personalized recommendations, no machine learning expertise required.
Amazon Forecast: Uses machine learning to deliver highly accurate time-series forecasts.
Typical Use Cases: “Customers who bought this also bought…” product recommendations, predicting retail demand, planning inventory and resource allocation.
🏗️ Full ML Platform (For Custom Models)
Amazon SageMaker: A complete end-to-end machine learning platform to build, train, deploy, and monitor your own custom models at scale.
The Rule of Thumb: Pick SageMaker when a pre-built, managed AI service does not exist for your specific, complex use case. The exam typically tests this by giving you a requirement that a standard service cannot fulfill, such as a highly specialized prediction task.
✨ 4) Generative AI: what AWS expects you to know
Generative AI questions usually focus on concepts and patterns more than deep implementation.
🧱 Foundation Models + Managed Access: The Engine of Modern AI
At the core of the generative AI revolution are foundation models. Understanding what they are and how to access them is key to leveraging this technology.
🧠 What is a Foundation Model (FM)?
A Foundation Model (FM) is a large-scale, pre-trained machine learning model. Think of it as a powerful, general-purpose “brain” that has been trained on a massive and diverse dataset (often encompassing vast amounts of text, code, or images).
Pre-trained: It comes with a broad, general understanding of language, concepts, and patterns, saving cost and time of training from scratch.
Adaptable: Its key power is adaptability. A single FM can be fine-tuned or prompted to perform a wide variety of downstream tasks it wasn’t explicitly trained for — from writing and translation to coding and analysis.
A common and crucial type of FM is the Large Language Model (LLM), which specializes in understanding and generating human language.
⚙️ Amazon Bedrock: The Managed Gateway to FMs
Amazon Bedrock is AWS’s fully-managed service that provides secure, single-API access to a curated selection of high-performing foundation models from leading AI companies like Anthropic (Claude), Meta (Llama), Cohere, and Amazon (Titan). Think of it as a unified platform where you can:
🔄 Experiment & Compare: Easily test different FMs with your prompts to find the best one for your use case.
🔒 Customize Privately: Securely fine-tune models using your proprietary data without it ever leaving the AWS ecosystem.
🧱 Build with Integrated Tools: Access built-in capabilities for key generative AI patterns, such as Retrieval-Augmented Generation (RAG), which grounds the model’s responses in your specific company data.
🧾 Prompting basics
It’s important to know the types of prompting
0️⃣ Zero-Shot Prompting: Asking the model to perform a task without any prior examples in the prompt. It relies entirely on the model’s pre-trained knowledge. Example: "Classify the sentiment of this text: 'The product works great, but delivery was late.'"
1️⃣ One-Shot & Few-Shot Prompting: Providing the model with one or a few examples of the task within the prompt to demonstrate the desired pattern or format before asking it to perform on a new input. Example: "Translate English to French. Example: 'Hello' -> 'Bonjour'. Now translate: 'Goodbye'."
⛓️ Chain-of-Thought (CoT) Prompting: Encouraging the model to show its reasoning step-by-step before giving a final answer. This is crucial for complex logical, mathematical, or planning problems where the “thought process” is as important as the answer.
🎯 Role-Based Prompting: Explicitly assigning a specific role or persona to the model to shape its perspective, expertise, and tone. Example: "Act as a seasoned marketing consultant. Draft a catchy slogan for a new eco-friendly water bottle."
📚 RAG (Retrieval-Augmented Generation)
Retrieval-Augmented Generation (RAG) is a pivotal pattern for building enterprise-ready generative AI applications. The process is straightforward:
- 🧑💻 A user asks a question.
- 🔍 The system retrieves relevant internal documents from a knowledge base (e.g., in Amazon S3).
- 🤖 A foundation model (e.g., from Amazon Bedrock) generates an answer using that specific context.
On AWS, this is implemented with services like Amazon Bedrock’s Knowledge Bases (handles retrieval) and Amazon OpenSearch or vector databases (for storage).
⚡ Why RAG Matters:
🎯 Reduces hallucinations by grounding answers in real data.
📈 Improves relevance with private, up-to-date company knowledge.
🏛️ Supports governance by providing known, auditable sources for every answer.
🆚 Prompting vs RAG vs fine-tuning
Choosing the right technique is key. Here’s a quick guide to the three main strategies for adapting foundation models:
🧾 Prompting: The fastest and cheapest method. You provide instructions and context directly in your request. Perfect for general tasks using the model’s built-in knowledge. Think of it as asking an expert a direct question.
🔎 RAG (Retrieval-Augmented Generation): The best choice when you need to use private, specific, or current data. It fetches relevant information from your own documents or databases and adds it to the prompt, grounding the answer in your context. Ideal for internal knowledge bases or up-to-date reports.
⚙️ Fine-Tuning: The most powerful adaptation. You retrain the model on your own dataset to deeply ingrain a specific behavior, style, or task. It’s best for needing consistent, customized outputs at scale (like a specific brand voice) but requires suitable data and more resources.
🛡️ 5) Responsible AI, security, and compliance (easy points if you prep)
⚖️ Responsible AI themes
- Bias/fairness: biased data → biased outcomes
- Explainability: important for regulated decisions
- Human-in-the-loop (Amazon A2I) : use where mistakes are expensive or high-risk
🔐 Security basics (practitioner level)
- Least privilege with AWS Identity and Access Management (IAM)
- Data protection: encryption in transit/at rest; be careful with logs and prompts
- Compliance/residency: requirements shape architecture decisions
Think “guardrails”: minimize sensitive data exposure and plan for monitoring and feedback.
📅 6) The two week plan
Here is the exact plan I followed to prepare for the exam. I had prior experience with GenAI, which allowed me to move efficiently.
🗺️ Days 1–2: Build Your One-Page Service Map
Sketch out a single-page reference that organizes AWS AI/ML services by the “job to be done.” This mental model is crucial for quickly navigating exam scenarios.
🧠 Days 3–6: Lock Down ML Fundamentals + Metrics
Cement your understanding of the core machine learning lifecycle (training, validation, testing), failure modes (overfitting, data leakage), and, critically, when to use precision vs. recall.
✨ Days 7–9: Master GenAI Patterns
Deep dive into Amazon Bedrock concepts, understand the RAG (Retrieval-Augmented Generation) architecture inside-out, and learn the trade-offs between prompting, RAG, and fine-tuning.
🧪 Days 10–12: Targeted Practice & Analysis
Work through practice questions. For every mistake, write down why you missed it. This active analysis is more valuable than the score itself and will highlight your specific knowledge gaps.
🔁 Days 13–14: Timed Review & Final Pass
Take a full-length, timed practice exam to build stamina. Use your final day exclusively to revisit and reinforce the weak areas you identified in the previous days.
🎯 7) Exam-day strategy (avoid common traps)
🔍 Read for constraints: latency, privacy, managed vs custom, real-time vs batch
🧩 Prefer managed services unless customization is required
🧠 Watch for “best” vs “possible” wording
✂️ Eliminate aggressively: usually two options are clearly wrong
😌 Don’t overthink math: it’s concept and service-selection heavy
🙂 Final thought
Stefan Mareek’s course gives you structure, but passing comes from turning that structure into decision instincts: What’s the simplest AWS approach that meets the need, safely and cost-effectively? If you can answer that consistently across scenarios, you’re ready.